【Python / Poetry】poetry の補完を zinit 管理下で使う
環境
- WSL2 (20H2)
- zinit
- poetry : v1.1.4
zinit 構成の詳細は こちら
前提
Pythonパッケージ管理ツールの poetry ではシェルの補完用スクリプトが用意されている(Zsh だけでなく OMZ や Prezto 向けにも手順が書いてある)。神。
一方、自環境は zinit で構築しているため、備忘録がてら本ブログに手順を記す。
解決策
以下の手順で補完用スクリプトを追加する。
- poetry 用のプラグインフォルダを作成 (なおpoetry自体は
curlコマンドでインストールした) - 補完スクリプトを追加
- zinit が管理する補完用のディレクトリにシンボリックリンクを追加
$ mkdir $ZINIT[HOME_DIR]/plugins/poetry $ poetry completions zsh > $ZINIT[HOME_DIR]/plugins/poetry/_poetry $ ln -s $ZINIT[HOME_DIR]/plugins/poetry/_poetry $ZINIT[HOME_DIR]/completions/_poetry
以上。exec zsh でリロードするのを忘れないこと。

『INRO: INSHIes DIE TWICE』
人生なんて回生の繰り返し。
はじめに
この記事は eeic アドベントカレンダー 2020 21 日目の記事です。
自己紹介
はい、いらっしゃいませ。
eeic2018 の いの(@inox4629music) と申します。B4 です。2 回目です。
タイトルにもあるように、私は夏冬 2 回の 院死1 を経て、院浪の身となった稀有な人生を送っています。「院死」で Google 検索すると 先人のブログが数多く出てきます2が、2 回も院死した方はそうそう出てきません。
どうしてこうなってしまったのか、
どうすればこんなことにならなかったのか、
これからどうしていけばよいのか。
このブログを訪れた物好きの方へ、3 度の院試を乗り越えた経験を拙筆ながら書き記していきます。
なお本稿は完全なる手記であり、これから院試を受ける方、院死を迎えてしまった方などへのお役立ちブログではないので悪しからず。
学部時代
理科一類出身、電気電子工学科に進学し、かつてブラック学科として栄華を極めた3 eeic の洗礼を受けながら 2 年間過ごしてきました。成績は中の下くらいでしたが、サボることなくそこそこ真面目に勉学に励んでいたと思います。
はじめは所属通り電電系の授業を取るも、ミーハーなので情報系に興味を持ち徐々に気持ちがシフトしていきました。正直大学に入るまでパソコンすらろくに触ったこともない赤子だったので、周りとのレベルの差は歴然。そうは言っても当社比では年を追うごとに成長していたこともあり、情報系研究室に進学する道を諦めるという考えはありませんでした。
vs 院試 1 回目
卒業研究のための基礎知識を再度学びつつ、初めてインターン(Web 開発系のバイト)を開始したこともあって 4~6 月はあっという間に消えていきました。6 月末あたりから院試勉強始めないとな~と思い対策し始めたのですが、何分にも学部時代はついていくので精一杯だったためほとんど身についておらず、到底時間が足りないという判断に至りました。悲しいね。
また苦手意識があった数学の勉強をしている余裕もないため、プログラミングで受験することにしました。
B4 夏。情報理工学系研究科創造情報学専攻に出願、不合格。
— いの (@inox4629music) 2019年9月2日
(余談ですが、専攻の出願理由は第一希望研究室が創造情報にしかなかったから、ただそれだけです)
結果としてプログラミングで大敗しました。
不合格の原因は偏に勉強不足でしょう。大コケをカバーできるほど専門の出来も良くなかったし。
ちゃんと数学の勉強しておけばよかった(したところで受かっていたかは定かではないが)。
院死(1 回目)直後
院死つら。
合格発表直後はこのくらいにしか思っていませんでした。直後はね。
つらいつらいと言えど、その程度の感想しか出てこないのは、なんだかんだ言って大学院には進学できるものという思い込みがあったからではないでしょうか。もちろん中間発表も約 2 週間後に控えていたこともあり、気持ちをシフトせざるを得ない状況にあったのは言うまでもないですが、心の奥底ではまさか自分が院試で人生計画がストップするとは夢にも思っていませんでした。なので 9 月時点で就活をするということもなく、卒論を早めに終わらせ冬院試に全力を注ぐという方針に決めました。親も心配こそすれど二十歳過ぎた子供にあれやこれや口出しすることもないので、了承してくれました。
ブログ中盤で結論になってしまうのですが、詰まるところこの「大学院には進学できるもの」という思い込みこそが、2 度の院死を迎える原因だったのではないかと考えています。院試は恐ろしいです。誰も幸せにしません(断言)。これが分かっていればちょっとは人生違ったのかな。たられば話ですが。ちょっとでも自信がない人は同学他研究科でも、他大でも、併願すべきです。併願先の面接官に「併願なんて甘い考えしてていいの?」という圧迫質問されたという噂話4もありますが、人生つらい思いしていいことなんて一つもありません。甘い汁を吸って生きましょう。
vs 院試 2 回目
この 2 年で一番精神的に辛かったのは 19 年 10 月~ 20 年 2 月でしょう。間違いないです。

中間報告も終わり 10 月になると、じわりじわりと院死が精神を蝕んでいきます。卒論提出日と冬院試の日程がもろ被り5なためなるべく早く書き上げたいと願っても、都合よく結果が出る訳もなく、ただ過ぎてゆく日々。周りは卒論に焦点を当て研究を進める中、TOEFL6 に金を払って I live in Tokyo... と呪文を唱え7、紙切れ 1 枚送るために追い課金。
思い出しただけでも辛くなってきたのでこのあたりで。
B4 冬。同専攻に出願、不合格。
院試は二度死ぬ pic.twitter.com/qxyNDsgW6I
— いの (@inox4629music) 2020年2月21日
正直受かったと思ってました。専門が比較的簡単、かつプログラミングも体感 7 割ほど解けたので得点率は問題なかったと思います。問題ないと思ったんですけどね~
これは確かなソースが無いのですが、冬院試の倍率は 6~7 倍あったとかなかったとか。少なくとも公式8で発表されている合格者が 42 人に対し志願者は 148 人。夏より倍率は高いでしょうから 4 倍以上であったことは間違いないなさそうです。狭き門ですね。
INRO の道へ
こうして冬院試でも不合格となった自分は院浪へ9。
先程最もメンタルが"底"だったのは 19 年後期と言いましたが、20 年前期、もはや院浪となった身にまともな精神なんてこれっぽちも残っていません。鬱でも躁でもなくあるのは無です。人生つら~という感覚すら麻痺します。布団に入っても寝ることすらできず、辛うじて起きてもあるのは虚無の人生。もはやこの先まともに人生を送る自信はとうに消え失せ、何をするにもやる気が出ない。そんな日々でした。
数か月後の自分の人生を保証できない状態が 1 年も続くとこんな感じになるんだなぁと学びました。
vs 院試 3 回目
ところでそんな自分の人生と並行して世間の情勢も大きく揺れていました。そうですね、流行り病です。
19 年度冬院試の時もかなり措置を取られていましたが、時が経つにつれ状況は悪化し、もはやオンサイトの試験実施すら危ぶまれるようになりました。初のオンライン試験ということもあり、受験生はおろか教授陣すら何も分からないという状態でした。そんな中で開示された 20 年度夏院試。なんと筆記試験消滅。えぇ…。
B4(2 回目) 夏。同専攻に出願、合格。
情報理工学系研究科創造情報学専攻合格しましたーーー!!!
— いの (@inox4629music) 2020年8月31日
文字通り三度目の正直!!!
ニート回避!!! pic.twitter.com/2BZqoK3HOS
(ちなみに工学系研究科にも出願していました。さすがにね。)
悪びれずに申し上げますが、流行り病の影響による試験内容の変更が圧倒的に有利に働きました。
筆記試験は無くなったものの、研究計画やこれまでの実績などを問うた書類審査10はかなり重く、A4 で 10 枚程度を要求されました。B4 一回目の自分であれば出願先を変えていたことは想像に難くないですが、卒論も書き終え、論文も提出していた自分にとっては比較的楽でした。正直。まぁ事前情報が一切皆無の口述試験はさすがに恐ろしかったけどね...。
晴れて合格。人生再スタート。
というわけで晴れて合格できました。崖際に立つ自分の背中をじわりじわりと押してくる院死ともおさらばです。
院死を繰り返した自分が言うのもなんですが、こんなもの生存バイアスです。今年の院試に落ちてたらどこで何をしていたかなんて分かりません。土の中に眠っていたかもしれません。本気でそう思うよ。
衣食住が保証された中でのたった 2 回の院死なんて大したことないと言われてしまうかもしれません。親にも院浪を許してもらえたし。ですが、あえて断言しておくと、この 2 年は自明に人生で最も辛い 2 年でした。そして最も大きな挫折でした。こんな経験二度としたくありません。
今 B3、B4 でこのブログに巡り合った方へ。院試頑張ってください。落ちるとつらいよ。
残念ながら院死を経てこのブログに辿り着いた方へ。院死、つらいよね。私でよければいつでも話し相手になります。あと辛くてもブログを漁ると色々と参考になることが見つかるかもしれません。
普通に受かった人へ。おめでとう。もし周りに院死した人がいればどうか励ましてあげてください。私は同期その他友人に変わらず接してもらったことで精神保てていました。ありがとう。
謝辞
完全に自己満なのでむしろ読まないで欲しい(?)
自分へ
よく頑張った。本当に頑張った。これからも一緒に人生頑張ろうな。
教授へ
こんなふざけたブログに名を載せるのは大変失礼で申し訳ないのですが、本当に教授方には助けて頂きました。なんの知識も技術もない自分の卒論をサポートしてくださり、院試に落ちた際も親身に相談して頂きました。ありがとうございました。そしてこれからも宜しくお願い致します。
親しい人へ
いつも心の支えになっています。恥ずかしいのでこの辺で。
同期ならびに友人へ
こんな取り柄のない自分ですが、周りの友人には本当に恵まれたと常日頃思っています。流行り病で直接会う機会は減っちゃったけど、院試に落ちた時も励ましてくれたり、バイトに誘ってくれたり、推しトークで盛り上がったり。圧倒的感謝。これからもよろしく。
推し
推しは神。
はかちぇ、叶くん、余はいいぞ。あまみゃもぇあ~もこんるるも葛葉もふわっちも明那もまゆゆもほんひまも天開司も久遠も最高なので全人類見ろ。
最後に
こんな重いブログを書いてしまいましたが、現在はめちゃくちゃ元気です。毎日こんな感じです。

P.S.
院試はクソ。
内部生は全員合格させろ。
【インフラ】TCP/IP 再入門【暇人の勉強ログ vol. 2】
レイヤとは
通信機能を階層に分割し、独立に開発可能とする。 「開放型システム間相互接続(Open System Interconnect)」、通称 OSI の設計方針に基づく。
L1: 物理層
伝送路 に関する問題を扱う。 どのようなケーブルを使うか、どのようなコネクタが必要か、それに合うインターフェースは?など。
L2: データリンク層
レイヤ 1 で疎通可能となった電気信号を「フレーム」という通信単位で扱う。
L2 スイッチとは
MAC アドレステーブルをもとに、物理ポートとその先に存在するネットワーク機器の MAC アドレスを変換する。 この L2 スイッチから直接接続できるネットワーク機器群を LAN と呼ぶ(多分)。
なお、MAC アドレステーブルを持っていない場合は「スイッチ」ではなく「ハブ」と呼ばれる。
L2 スイッチ の動作例
PC A から、IP アドレス 192.168.1.6 にある PC B にトラフィックを送信するとする。 レイヤ 2 スイッチ環境内のブロードキャストドメインを元に、ブロードキャストパケットを受信したポート以外の全てのポートにブロードキャストトラフィックが転送される。ここで、ブロードキャストはレイヤ 3 境界を越えることは出来ないため、同じセグメント内に含まれる。
しかし、PC B の固有 MAC アドレスは、ARP によって検出されるまでわかりません。ARP はレイヤ 2 セグメント全体にブロードキャストされる。 適切な宛先 MAC アドレスにパケットが送信された後、スイッチにより、MAC アドレス テーブルに基づいて正しいポートに転送される。
L3: ネットワーク層
レイヤ 2 で構築された LAN 同士の接続を実現する。 レイヤ 3 では、データ列を「パケット」という単位で扱い、各端末にはレイヤ 3 用のアドレス (=IP アドレス) が割り当てられる。
L3 スイッチとは
ほぼルータと同じ。パケットの宛先を判断して転送を行う。
が、レイヤ 3 スイッチが「多くのポートを備えたルータ」ではない。
VLAN
Virtual LAN のこと。 物理的議論では、LAN =「同じスイッチに接続された端末群」としていたが、VLAN は物理的な接続に関係なく互いに接続できるグループを構成する。
VLAN のメリット
VLAN 機能を使えば、同じスイッチに接続されていても別の VLAN 内に構成されている端末との通信が出来なくなる。
レイヤ 3 スイッチの必要性
メリットの裏返しとして、1 つのスイッチに接続している端末同士でも、VLAN 機能を利用していると VLAN 間の通信にはルータが必要になる。これにより開発された LAN スイッチにルータの機能を組み込んだ装置が、レイヤ 3 スイッチである。
L3 スイッチの動作例
VLAN 間で(2 つの VLAN インターフェイスを通じて)ルーティングを実行するレイヤ 3 スイッチングの例は以下の通り。VLAN 20 にブロードキャストされた ARP 要求による PC B の MAC アドレス解決をもとに、適切な宛先 MAC アドレスに書き換えられ、レイヤ 2 セグメントからパケットが返送される。
ネットワーク分割
ネットワーク分割の方法 3 種
- 物理的に分割
- 論理的に分割
- IP アドレスでの分割
- VLAN での分割
目的
セキュリティ上の理由 がメジャー。 セグメント内での通信は許可するが、セグメントを跨ぐ L2 通信はさせたくないのが目的となる。 特に L2 通信で代表的な ARP は基本的にブロードキャストで LAN 内にパケットが送られるため、ネットワーク内部でキャプチャされていた場合、他セグメントの情報も確認できてしまう。
物理的に分割
解:レイヤ 2 スイッチを分ける
ここで注意しなければならないのは、分割しているのは イーサネットのネットワーク である。
IP アドレスでの分割
IP アドレス(サブネット分割)により論理的に分割することもできる。
ここで注意しなければならないのは、物理的に同じイーサネットネットワークで構成されていた場合、ブロードキャスト / マルチキャストなどがフラッディングしてしまう。
VLAN で分割
VLAN の章で述べた通り、論理的にスイッチを分割し、イーサネットネットワークを分割する。
IPv4
割り当てできない IP アドレス
- ネットワークアドレス
- ホスト部のビットが全て 0 のもの
- 10.0.0.0 や 192.168.1.0 など
- 0.0.0.0/0 は全ての IP アドレス範囲を示す。
- ブロードキャストアドレス
- ホスト部のビットが全て 1 のもの
- 10.255.255.255 や 192.168.1.255 など
IP アドレスの範囲と表記
- CIDR (Classless Inter-Domain Routing) 表記
- 「サイダー」と読む
- アドレスの後ろに、
/n(n: プレフィックス。ネットワーク部のビット長) と書く - ex)
192.168.0.0 ~ 192.168.255.255=192.168.0.0/16
- サブネットマスク表記
ルーティングプロトコル
新たなネットワークを追加するとき、その情報をルーティングテーブルに反映させる。
EGP
Exterior Gateway Protocol の略。 AS (Autonomous System) 間の境界上に位置するルータ同士が経路情報を交換し合うためのプロトコルのこと。現在は BGP (Border Gateway Protocol) が主流。
ISP(Internet Service Provider) や AWS などの AS は、固有の AS 番号が割り振られている。BGP では、BGP ネイバー(ルート情報を交換する BGP ルータ)に BGP テーブル上のベストパスのルート情報を AS 番号とともにアドパタイズする。
IGP
Interior Gateway Protocol の略。 AS 内部で完結する経路制御プロトコルを呼ぶ。RIP (Routing Information Protocol) や OSPF (Open Shortest Path First) が主流である。
RIP はディスタンスベクタ型と呼ばれ、宛先ネットワークまでの距離を表すメトリック(RIP はホップ数)であるディスタンスと、ネクストホップとインターフェースに相当するベクタを用いてルート情報を表現する。また 30 秒ごとにルート情報を送信し合うことで、送信しているルート情報のネットワークが正常に稼働していることを他の RIP ルータに通知している。一方ルータ数が多くなると、コンバージェンス(収束)時間が長くなるため、障害発生時に削除すべきルート情報が残り続けルーティングループが発生する可能性が高い。小規模ネットワーク向き。
OSPF は リンクステート型と呼ばれ、ルータ同士は単純なネットワークアドレス/サブネットマスクではなく、LSA(Link State Advertisement) を交換する。ネットワークを「エリア」と呼ばれる小さな単位に分割して経路情報を管理しており、同一エリア内のルータは全て同じトポロジデータベースを保持する。他のエリアからは内部の詳細なトポロジは見えないようになっており、経路情報の削減に貢献している。中規模ネットワーク向き。
ICMP
Internet Control Message Protocol の略。
ping コマンドを実現しているプロトコルである。IP プロトコルの「エラー通知」や「制御メッセージ」を転送するために利用される。
NAT
知っていることが多いので略
Linux コマンド
lsof
実行中のプロセスを調べる。
$ sudo lsof -i -n -P COMMAND PID USER ... NAME dhclient 1017 root ... *:68 sshd 1147 root ... *:22 (LISTEN) ...
LISTEN が「待ち受け状態」、 ESTABLISHED が「通信中のポート」を示す。
AWS 予備知識
AL2 と RHEL
- Amazon Linux 2 は、RHEL 7 (「レル」と読む)系
- Amazon Linux AMI (前バージョン) は RHEL 6 系と言われている
- RHEL とは Red Hat Enterprise Linux の略で、Linux ディストリビューションの一つ。
- 以下のような特徴を持つ
- 安定性重視 (サーバ用 OS として利用される)
- 有償
- サポートが充実 (toB)
Apache と Nginx
Web サーバ用のミドルウェア。OS とアプリケーションを仲介する。
Apache
- マルチプロセスのプロセス駆動アーキテクチャ を採用
Nginx
C10K 問題
- Apache の(?)マルチプロセスに付随する問題を指す
- クライアント数が 1 万 (=10k)を越えると、「ハードウェア性能に余裕があっても」「プロセス数の上限に達し」「リクエストの応答性能が極端に低下する」
- これを解決するのがシングルスレッド & 非同期・ノンブロッキング I/O
追々更新していく。
その他参考
- LAN スイッチ - Cisco
- VLAN のレイヤ 3 スイッチとレイヤ 2 スイッチの比較
- Apache と Nginx について比較 - Qiita
- いまさら聞けない Node.js | さくらのナレッジ
布教コーナー
ここからが本編だぞ!
以前紹介した 葉加瀬冬雪 さんにどっぷりハマり中。
「指示厨殺し」と言われるほど自由気ままでマイペースなゲーム実況で有名ですが、それ以上に、いや誰よりも何よりも「配信がしたい!」という気持ちが伝わってくる姿がとても素敵なVTuberです。
最近は諸々で忙しそうですが、彼女のやりたい事や夢に向かって全力で楽しんでほしいなぁと、一介の モルモット リスナーとして応援しています。
「死んだら即終了SEKIROシリーズ」はオススメ。短いし 面白いし、毎日0時スタートなのでとても見やすい。配信したいけど長時間は取れない…、そんな中、逆転の発想でこういう企画で楽しませてくれる はかちぇには頭が上がりません。
今日こそ大手門が開くのだろうか… www.youtube.com
今週金曜日(10月23日)は!!!はかちぇの!!!3Dお披露目!!!見ろ!!!
【AWS】インフラ志望なのにAWS触ったことないってマジ?と言われないために勉強した【暇人の勉強ログ vol. 1】
はじめに
ニートを極めると勉強する習慣すら消え去っていくので、リハビリがてらAWSの再入門をしました。
参考資料
基本的に以下の書籍を読んだというブログです。
https://www.amazon.co.jp/dp/B084QQ7TCF
(はてなブログって商品画像のプレビューできなかったっけ…?)
AWS の基本
サーバ
- そもそもサーバは、適当な OS にどのようなソフトウェア (ミドルウェアとも)をインストールするかでその役割が決まる
リージョンとアベイラビリティゾーン
- 「リージョン」
- 「アベイラビリティゾーン」
- 各リージョンをさらに分割したもの。
- AZ は独立したファシリティを用い、耐障害性を高めている。
- アジアパシフィック(東京)リージョンは"ap-northeast-1a"、"ap-northeast-1c"、"ap-northeast-1d"の 3 つの AZ から構成されている
- 同リージョンの AZ 間は専用線で結ばれているだけでなく、データの複製や他 AZ のリソースの参照など可能である。
ネットワークと VPC
- Amazon Virtual Private Cloud
VPC 作成と同時に作成されるもの (予想)
Amazon DNS
VPC 内で利用可能な DNS サーバ
CIDR の 3 番目のアドレスを使用(10.0.0.0/16 の場合は 10.0.0.2)
Router
VPC 内のルーティングを行う。VPC 内のサーバのデフォルトゲートウェイは全てこれ。
Default Route Table
デフォルトとなるルートテーブル。VPC 内は自動でルートを持ち、削除不可である。
インターネットゲートウェイ
VPC 内パブリックサブネットのデフォルトゲートウェイとして設置される。 ルートテーブルは、以下のようになる
| dst | target |
|---|---|
| 10.1.0.0/16 | local (VPC 内) |
| 0.0.0.0/0 | Internet Gateway |
IGW における「VPC にアタッチ」とは、以下の図でイメージされるように VPC 内の Router と IGW を接続することであると理解できる。

一方、「パブリックサブネットをインターネットに接続する」(=作成したサブネットをパブリックとして扱う)とは、ルートテーブルに {dst: 0.0.0.0/0, target: IGW} を追加することである。
IAM
適当に作る
作業手順
VPC の作成
- コンソールから「VPC」を選択し、作成
- name: my-first-VPC
- CIDR: 10.0.0.0/16
- サブネットを作る
- ゲートウェイを作る
- パブリックサブネットとインターネットとを接続する
- ルートテーブルを作る
- VPC を作成した時点でルートテーブルが作成されている
- dst: 10.0.0.0/16, target: local
- これは、VPC 領域の CIDR ブロック宛のパケットは、全て local(=自身のネットワーク)に流される。それ以外は破棄。
- サブネットを作成すると、上記のルートテーブルがデフォルトとして設定されている
- デフォルトゲートウェイをインターネットに向けて設定
- VPC を作成した時点でルートテーブルが作成されている
EC2 の作成
t2.microで作成- VPC を設定
- ネットワークインターフェイスからプライマリ IP =
10.0.1.10を設定 - ストレージを Elastic Block Store の 8GB を選択
- インスタンスを「停止」してもストレージは止まらないので注意。
- セキュリティグループを設定。とりあえず「マイ PC」に制限。
- キーペアを作成。多分秘密鍵のこと。
- 適当に保存。
SSH 注意事項
- 起動 / 停止のたびにインスタンスのグローバル IP は変わるので注意
- 固定したかったら Elastic IP を使う
- なんらかのタイミングで「マイ PC」の IP アドレスが変わるので注意
- プロバイダの気分次第
- 秘密鍵の権限は 400 にする
- ユーザ名は
ec2-userであることに注意- IAM のユーザ名ではないっぽい
- 他 OS の場合、デフォルトユーザ名が異なるらしい
Web サーバソフトのインストール
略
DNS サーバの構成
- VPC コンソールから該当の VPC を選択し、アクション -> DNS ホスト名を編集 を選択。有効化にチェック。
- EC2 コンソールに「パブリック IPv4 DNS」が増える
- http://ec2-xx-xxx-xx-xxx.ap-northeast-1.compute.amazonaws.com のように割り振られる。
- 「プライベート IPv4 DNS」は VPC 内でのみ参照できる
- 独自ドメインを使用する場合は、 Route53 などを利用する。
EC2 内から nslookup を実行すると次の通り。
[ec2-user@ip-10-0-1-10 ~]$ nslookup ec2-xx-xxx-xx-xxx.ap-northeast-1.compute.amazonaws.com Server: 10.0.0.2 Address: 10.0.0.2#53 Non-authoritative answer: Name: ec2-xx-xxx-xx-xxx.ap-northeast-1.compute.amazonaws.com Address: 10.0.1.10
これより、VPC 内で DNS サーバが 10.0.0.2 に、EC2 サーバには 10.0.1.10 が割り当てられていることが分かる。
プライベートサブネットの作成
インターネットからの接続を拒否したネットワークを作成する。 しかし安直に作るとインターネットに接続することも出来ないため、NAT を適切に構築する。
基本的には「EC2 の作成」と同様。10.0.2.10 を割り当てた。
プライベートサブネット内のサーバに SSH
踏み台サーバを経由する。
NAT の構成
NAT をファイアウォール(IP フィルタ)のように用いて、プライベートサブネット内のサーバからインターネットへの接続を可能にする。
具体的には、パブリックサブネットのデフォルトゲートウェイには IGW を、プライベートサブネットには NAT-GW を関連付ければよい。
編集中、メインルートテーブルを変更したところ戻せなくなった。
そもそも「ゲートウェイルートテーブルをメインルートテーブルとして設定することは出来ません」とあるのに何故変更できたのか…
参考
【CI/CD的な】GitHub Actionsを使ってビルドからrsyncでデプロイまでを自動化する
はじめに
冷静な自分が「本当にこんなことやっている場合か...?」と自身に語りかけるが、費やした時間は返ってこない。本記事を執筆することで今日一日の代償を払うことにした(勉強しろ:angry:)。
TL;DR
GitHub Actions を使って、ビルド&デプロイ を自動化したよ
GitHub Actions とは
GitHub 上のさまざまな操作 (push だけでなく PR とか issue とかを対象としたモノもある) をトリガーに、YML で記述しておいた処理を実行できる機能のこと。昨年 2019 年末に一般ユーザにも解禁されたため、手軽に CI/CD っぽい操作ができるようになった。
先日 HTML と JS だけのシンプルな Web ページを一発で公開できる Webpack & ディレクトリテンプレートを作ってみた1 趣味プに時間費やしすぎ 。この時は主に Netlify と連携することにより自動デプロイすることを目論んでいたが、折角研究室から貸与されているサーバで Apache も構築してあるので、ここにデプロイしよう!と思い立った。
本記事では、この GitHub Actions(以下 GA)を利用して、develop ブランチが更新される度に自動ビルド & デプロイが行われるよう設定した。
用意するもの
- GA が使えるアカウント
- 適当なレポジトリ
- 自環境では、先述のテンプレートから派生させたレポジトリを用いた。このプロジェクトは
index.htmlや 諸 CSS ファイルは全てpublic/下にあり、yarn buildを実行するとsrc/下のビルドファイルであるpublic/dist/app.jsが生成されることを念頭に置いて頂きたい。
- 自環境では、先述のテンプレートから派生させたレポジトリを用いた。このプロジェクトは
- 自前サーバ。
手順その 1. Web サーバの準備
以下、{{}} で表現される内容はメモ書きであり、各自環境に合わせて記述して頂きたい。無論 {{}} を書く必要はない(YML 内の ${{}} は例外である)。
1.1. Apache, sshd, rsync の設定
がんばる。
1.2. 鍵の生成
GA から自前サーバへ SSH 接続を行うために鍵を生成する。暗号強度は個人差があります。
$ ssh-keygen -t rsa -b 4096 -f {{ YOUR_KEY_NAME }}
公開鍵は、自前サーバの ~/.ssh/authorized_keys に追記しておけばよい(多分)。秘密鍵を 丁寧に GitHub の SECRETS へ格納する(画像参照)。名前は何でも良い(ここでは SSH_SECRET_KEY とする)。

手順その 2. GitHub Actions の準備
ここでは、以下を目標とする。
develop(=リポジトリのデフォルトブランチ) への push によって発火する。- package.json に記述した
yarn buildコマンドを実行し、ビルド。 rsyncによってpublic/下のファイルをデプロイ先指定のディレクトリに同期する。
YML の記述
リポジトリの Actions タブへ移動すると、"Get started with GitHub Actions" というページが登場する。AWS へのデプロイ等、巨人の肩の上に立つことができる場合はワークフローを Fork すればよいが、ここでは "Skip this and set up a workflow yourself" を選択し、ワークフローを自作する。
GA のワークフローは YML ファイルで記述する。長々しい説明を書くのは疲れたため、最終的なコードは以下を参照されたい。
# deploy.yml # ワークフローの名前 name: { { YOUR_WORKFOW } } # トリガーの指定。言うまでもないが、以下は「 develop branch に push した時」となる。 on: push: branches: - develop # 実行する処理を記述する。 jobs: deploy: # 走らせる仮想環境を決定する。 runs-on: ubuntu-latest steps: # develop ブランチを参照する。後ほど詳述。 - uses: actions/checkout@v2 with: ref: develop # `uses` コマンドに対しては名前を付けることも可能。 - name: Node setup uses: actions/setup-node@v1 # ビルドコマンドを走らせる。installを忘れないこと。 - run: yarn install && yarn build # 秘密鍵に対する設定。やや回りくどいのは permission 変更のためだと考えている - name: ssh key generate run: echo "$SSH_SECRET_KEY" > key && chmod 600 key env: # ここの `secrets` が GitHub 内での API である模様。直後のプロパティ名は手順1.2. で保存したものと同名であるように注意。 SSH_SECRET_KEY: ${{ secrets.SSH_SECRET_KEY }} # 同期のための rsync コマンド。後ほど詳述 - name: rsync deploy run: rsync --checksum \ -av \ --delete \ --exclude '{{ YOUR_PATTERN }}' \ -e "ssh -p {{ PORT }} -i key -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no" \ ./public/* \ YOUR_USERNAME@YOUR_SERVER_NAME:/path/to/apache_root/
2.1.1. actions/checkout@v2 について
YML ファイル内、uses コマンドは他者が公開しているコードを利用する機能である。
ここでは GitHub 公式が公開している checkout ライブラリを用いる。このライブラリは、名の通り git のチェックアウトを行う。with: ref: BRANCH_NAME を引数に与えることで指定されたブランチへと移動し、そのクローンファイルに対して期待の処理を実行できる。他にも当該リポジトリだけでなく、他リポジトリを交えた処理も可能なので、README.md を参照されたい。
なお、ref 引数を与えない場合、デフォルトブランチで操作が行われるため、develop 等に変更している場合は注意が必要である。
2.1.2. rsync について
rsync とは、UNIX システムにおいて差分符号化を行って(比較的)高速にデータ転送を行うソフトウェアである。個人的に scp が一般的であるイメージを持っているが、OpenSSH がそのリリースノートで「scp は非推奨」との声明を出している(ソースは各自調べて)。
rsync は差分転送が可能であり、Git のバージョン管理とも相性がよいことから今回のデプロイで採用した。
先述の rsync コマンドの内容を再掲する。
$ rsync --checksum \ -av \ --delete \ --exclude '{{ YOUR_PATTERN }}' \ -e "ssh -p {{ PORT }} -i key -o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=no" \ ./public/* \ YOUR_USERNAME@YOUR_SERVER_NAME:/path/to/apache_root/
以下、注意すべきポイントを説明する。
- dry-run オプション
- 同期であるが故の悲劇も起きうる2。まずはこれを付けて確認すべし。
- checksum オプション
- デフォルトでは「タイムスタンプ+ファイルサイズ」をハッシュ化し、差分の有無を確認している。しかし GA 上では、ファイルのクローンが作成される(要検証)ため、タイムスタンプが都度更新され、中身に更新がない場合でも転送されてしまう。checksum 判定に変えることでこれを回避し、ファイルの中身のみで判定するようにする。
- ファイル数が多い場合、checksum の計算に CPU リソースを消費してしまうが、
GA なのでヨシ!
- a オプション
- バックアップ用途の場合、とりあえずこれを付けておけば ok
- v オプション
- verbose は義務
- delete オプション
- 「削除」を反映させる。
- 取り扱いには要注意。
- exclude オプション
- e オプション
- リモートシェル(=通常 ssh)を指定する。
- rsync daemon を同期先に常駐させておくことが理想的(?)であるが、秘密鍵暗号方式で行うやり方が分からなかったので over ssh とした。
- ポート番号や鍵の指定方法はコードの通り。
-o UserKnownHostsFile=/dev/null -o StrictHostKeyChecking=noとあるが、現在時点では必須である。通常、新しいホストからSSH接続する場合fingerprintを~/.ssh/known_hosts等に記録するステップが踏まれるが、GAでは対話的実行ができないためこれを省略する。MITM攻撃に脆弱となってしまうため、解決策があれば積極的に改善したい。
- [SOURCE][dist]
- 最後に「同期元ファイル」「同期先ファイル」を指定して転送開始。
- 同期元ファイルに関して、末尾に
/を付けるか否かで大きく挙動が変わるので注意されたい。私は明示的に*ワイルドカードを使うことを推奨する。
以上。

疲れたけど一日で終わらせたので、まぁ良しとする。
あとがき
最近魚がポケモンを操作する時代になったんですよ。
しかも何千もの人がそれを見守っているらしい。
自分はBGMとして聴いていますが、とても複雑な感情になれるのでオススメです。
ちなみに自分の推しは ア!!エッ 。
(追記) 推し解雇されてて草
(追々記) 名前が変わっていたらしい。おもしろ。
【JavaScript】async constructor がしたい
はじめに
卒論で書いたコード(JavaScript SPA)があまりにも汚かったので、最近オブジェクト指向 & モダンなJSを使って書き直してます。 そんな中での一幕。
async constructor() ができない
例えば以下のようなクラスを書いたとします。
import * as THREE from "THREE" class Hoge { constructor() { this.scene = new THREE.Scene(); } addCamera() { this.scene.add(new THREE.Camera()); } } function main() { const hoge = new Hoge(); hoge.addCamera(); }
一見大丈夫そうですが、これでは Uncaught TypeError: Cannot read property 'add' of undefined と言われてしまいます。
addCamera() が非同期に実行されたため THREE.Scene のインスタンス生成が終わらぬ間に呼び出されたと推測できます。
それなら、と以下のコードを書いてみる。
class Hoge { async constructor() { this.scene = await Promise.resolve(new THREE.Scene()); } // 以下略 }
これも残念ながら Uncaught SyntaxError: Class constructor may not be an async method と言われてしまいます。コンストラクタにはasyncがつけられない模様。
現状の対応
とりあえずこんな感じで書いてる。
class Hoge { constructor() { this.scene = null; // 当然だが無くても動く。プロパティを明示するために書いたが、TypeScript使えやと言われそう。 } static async build() { const hoge = new Hoge(); hoge.scene = await Promise.resolve(new THREE.Scene()) return hoge; } addCamera() { this.scene.add(new THREE.Camera()); } } async function main() { const hoge = await Hoge.build() hoge.addCamera() }
自分の思いつく範囲では、「インスタンスをPromiseで返す」か「コンストラクタ単体でのインスタンス生成を諦める」かの2択になる。前者はさすがに気持ち悪い(instance.then(...) は違和感しかないだろ…)ので、後者を選択。コンストラクタ以外ならクラスメソッドもインスタンスメソッドでもasync構文が使えるようなので、 new THREE.Scene() を待ってプロパティに格納する。
私はJSょゎょゎなので、これ以外の方法があればご教授ください。
あとがき
最近オススメのVTuberは、断然にじさんじ所属の葉加瀬冬雪(通称 はかちぇ)。先日遂にメンバーシップに加入してしまった...。
ゲームがそれほど上手いわけじゃないけど、「指示厨殺し」だけど いつも楽しそうに配信している姿は元気もらえます。
実は歌も上手いんですよねぇ…。この空奏列車のカバーを初めて聞いたときは本当に心が震えました。今日公開のオリ曲にも期待。
Kubernetesの勉強
はじめに
ネットワーク研にいるのに、k8s も知らないのはなんかダメだなぁと思ったので勉強してみる。
参考
kubernetes とは?
Kubernetes とは、オープンソースのコンテナーオーケストレーションツールである。
そもそもコンテナとは
コンテナとは、ホスト OS 上に論理的な区画を作り、あるアプリケーションを動作させるのに必要なモジュール(ライブラリとかアプリケーションとか)を一つにまとめたもの。
なぜ他の仮想化技術に比べて軽量?
コンテナは Linux の通常のプロセスとほぼ同じ処理らしいが、それぞれのプロセスを 1 つのグループとして管理する(Linux で言えば namespace や cgroups などのカーネル機能とか) ことで、名前空間やリソースを他のプロセスやコンテナから隔離することができる。
- ホスト型
- Oracle VM VirtualBox など
- ゲスト OS over 仮想化ソフトウェア over ホスト OS over ハードウェア
- スーパバイザ型
Docker の特徴
Docker は、「コンテナ型仮想化」の代表例。
Docker が出来ることは、
- コンテナの作成
- コンテナの実行
- コンテナ内でファイルシステムとして使われるイメージの作成・管理
逆に出来ないことは、
- ネットワークのルーティング
- 複数コンテナの連携
- 複数台のサーバを対象としたコンテナの横断的な管理
コンテナオーケストレーションツールの必要性
コンテナオーケストレーションツールとは、すなわちコンテナを統合管理できるツールのこと。
シングルホストでは手軽なコンテナも、マルチホストで運用する際は、以下のような要求を満たさなければならない。
- コンテナの操作(起動、停止、削除)
- ホスト間のネットワーク接続
- ストレージ管理
- コンテナ-ホスト間のスケジューリング機能
Kubernetes
特徴
- 複数サーバでのコンテナ管理(グルーピング)
- コンテナのデプロイ
- コンテナ間のネットワーク管理
- コンテナの負荷分散
- コンテナの監視
- コンテナのアップデート
- 障害発生時の自動復旧
アーキテクチャ1
k8s アーキテクチャ概要図 (https://github.com/kubernetes/kubernetes/blob/release-1.3/docs/design/architecture.md)
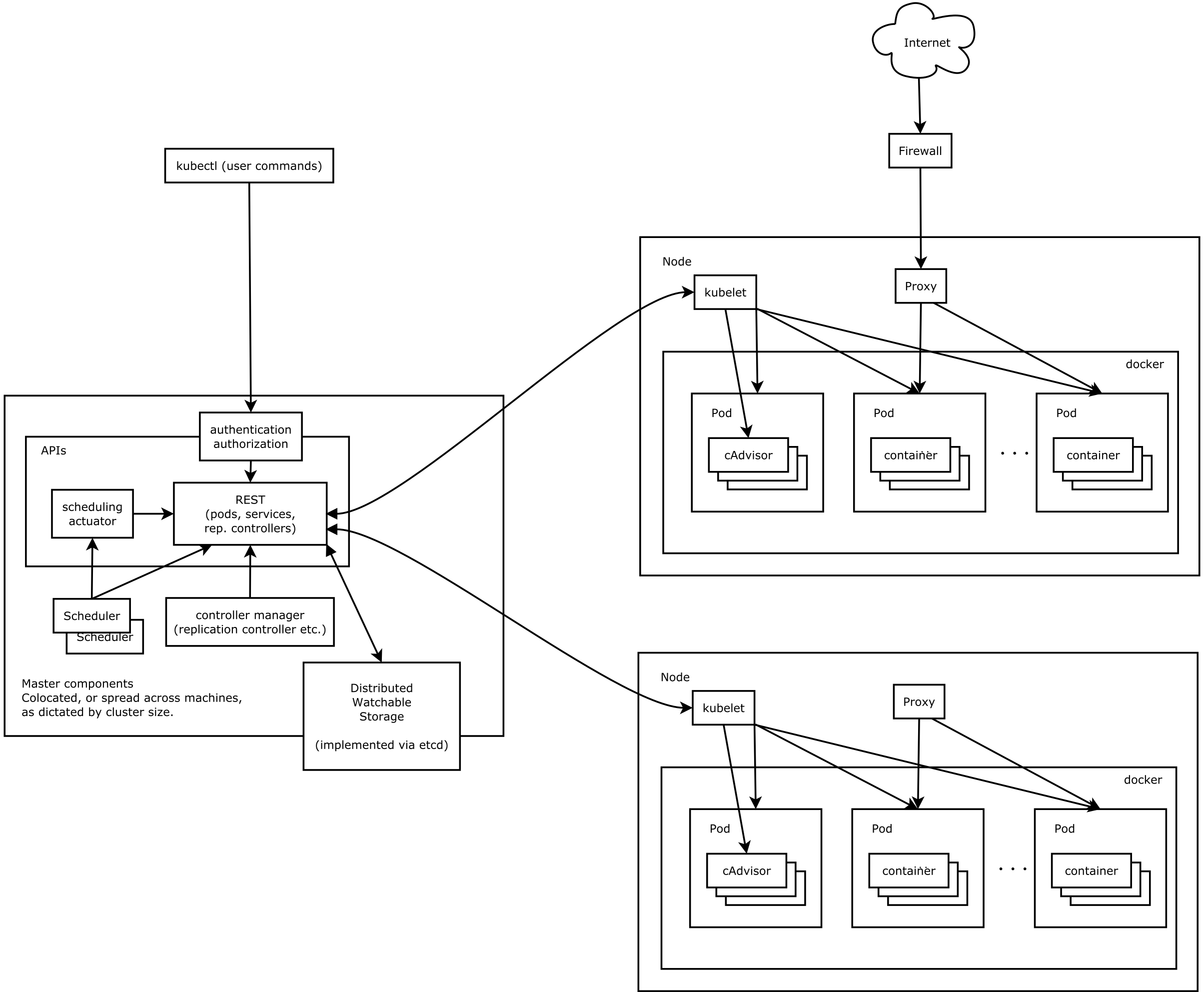
コンポーネント
k8s は、1) マスターコンポネント と 2) ノードコンポネント により成る。
- Master
- Node
- コンテナアプリケーションを動作させるサーバ群
- ノードは複数台でクラスタを構成
- kubelet
- Pod の定義ファイルに従ってコンテナを実行したり、ストレージをマウントしたり。
- Node のステータス管理も行う
リソース
- Pod
- 複数のコンテナをまとめたもの
- アプリケーションのデプロイの単位となる。
- 同じ Pod のコンテナは、同じ Node 上に構築される。
- ReplicaSet
- クラスタ内で指定された数の Pod を起動しておく仕組み
- Service
- Kubernetes のネットワークを管理。
- コンテナアプリケーションへのアクセス方法を決めるリソースのこと。
- ポート番号やプロトコル、負荷分散のタイプなどを設定。
コンセプト
インフラ構成管理
| 今まで | これから |
|---|---|
| オンプレ | クラウド |
| メンテナンス | 仮想化 |
| 長期運用 | Immutable Infrastructure |
| システム構築の手順や変更履歴を管理 | 宣言的設定 |
- Immutable Infrastructure
- 一度構築したインフラは変更を加えない。
- 変更または不要となった場合は、破棄して新しいものを作る。
- 宣言的設定
- システムの状態を管理
- 自己修復が可能
Kubernetes を支える仕組み
- スケジューリング
- アプリケーションを適切なところにデプロイする仕組み
- サービスディスカバリー
- デプロイされたアプリケーションがどこに(サーバまたはノード)あるか見つけ出す
- 構成レジストリ
- サービスディスカバリーに用いる、インフラとサービスを動的に紐づけるもの。
Azure
リソースグループ
- Azure が管理する、論理的な単位。
- Azure ユーザが使うレジストリもこのグループで分割管理してそう。
Azure Container Registry
コンテナイメージの共有サービス。
- 複数リージョン間でのレジストリ管理
- セキュリティと CI/CD 管理
- コンテナイメージの自動ビルド
Azure Kubernetes Service
Kubernetes クラスタを管理するパブリッククラウドのサービス。
サービスプリンシパル
ACR 内のコンテナイメージを取得するためのアクセス権限を、AKS に与えるために用いる。
作業
[ACR] コンテナイメージの作成
- リソースグループの作成
$ az group create --resource-group $ACR_RES_GROUP --location japaneast - レジストリの作成
$ az acr create --resource-group $ACR_RES_GROUP --name $ACR_NAME --sku Standard --location japaneast - サンプルコード(コンテナイメージ)の clone
$ git clone git@github.com:ToruManabe/Understanding-K8s - イメージのビルド
$ az acr build --registry $ACR_NAME --image photo-view:v1.0 v1.0/
[AKS] 連携
- サービスプリンシパルの作成
$ az ad sp create-for-rbac --name $SP_NAME --role Reader --scopes $ACR_ID --query password --output tsv - クラスタの作成
$ az aks create --name $AKS_CLUSTER_NAME --resource-group $AKS_RES_GROUP --node-count 3 --kubernetes-version 1.11.4 --node-vm-size Srandard_DS1_v2 --generate-ssh-keys --service-principal $APP_ID --client-secret $SP_PASSWD
ここでエラー発生…
Operation failed with status: 'Bad Request'. Details: The VM size of AgentPoolProfile:nodepool1 is not allowed in your subscription in location 'japaneast'. The available VM sizes are ...
とのこと。
仕方ないのでポータルの方を見に行く。確かに、利用できる VM のサイズは限られており、「汎用」ファミリは使えないよう。なんでや。
未指定も怖いので、とりあえず一番安い Standard_F2s_v2 にしてみる。
また怒られた。
Operation failed with status: 'Bad Request'. Details: Provisioning of resource(s) for container service testAKSCluster in resource group testAKSCluster failed. Message : Operation could not be completed as it results in exceeding approved Total Regional Cores quota. Additional details - Deployment Model: Resource Manager, Location: japaneast, Current Limit: 4, Current Usage: 0, Additional Required: 6, (Minimum) New Limit Required: 6. ...
よく分からないが、作成したリソースグループの容量の都合上、作成できるノード数が 2 つまでだったらしい。CLI だとこういう問題の同定がしづらいよな…
以下でようやくクラスタが作成できた。なお、2020/04/02 現在、既定の k8s version は、1.15.10であった。
$ az aks create \ --name $AKS_CLUSTER_NAME \ --resource-group $AKS_RES_GROUP \ --node-count 2 \ --node-vm-size Srandard_F2s_v2 \ --generate-ssh-keys \ --service-principal $APP_ID \ --client-secret $SP_PASSWD