「データサイエンス 100 本ノック(構造化データ加工編)」をやる
研究もバイトもやる気出ね~~~って時の逃亡先
逃亡してる暇があるのかと言われたら…
ソース
The-Japan-DataScientist-Society/100knocks-preprocess: データサイエンス 100 本ノック(構造化データ加工編)
知らなかったもの
クオーテーション
:star: 文字列はシングルクオーテーションで囲むのが無難。
| SQL | single | double |
|---|---|---|
| MySQL | 文字列定数 | 文字列定数 |
| PostgreSQL | 文字列定数 | カラム名 |
| 標準 SQL | 文字列定数 | カラム名 |
BETWEEN
カラム名 + BETWEEN + 下限 + AND + 上限 の順。
SELECT * FROM receipt WHERE amount BETWEEN 1000 AND 2000;
NOT
NOT column_name = ?VALUE の順。
!= も使える
-- 例 WHERE customer_id='CS018205000001' AND NOT product_cd = 'P071401019';
LIKE
便利。
store_cd が "S14" から始まるものは以下のクエリより求まる
select * from store where store_cd like 'S14%' LIMIT 10;
:star: 「~を含む」という検索も、LIKE '%~%' とすれば良い。
COLUMNS
テーブル情報の確認に使う MySQL と PostgreSQL で違う
# MySQL SHOW COLUMNS FROM customer; # PostgreSQL SELECT * FROM information_schema.columns WHERE table_name = 'customer' ORDER BY ordinal_position;
正規表現
MySQL は regexp 演算子を使う
PostgreSQL は ~ 演算子を使う
# MySQL select * from customer where status_cd regexp '^[A-F]' LIMIT 10; # PostgreSQL select * from customer where status_cd ~ '^[A-F]' LIMIT 10;
ORDER BY の逆順
「逆順」って言われると一瞬分からなくなるよね
デフォルトが 昇順 ASC、逆が 降順 DESC
ランク機能
SQL により使える関数が異なる。
MySQL は FIND_IN_SET() と GROUP_CONCAT() を組み合わせる
PostgresQL は RANK() OVER() 関数を用いる
# MySQL select *, FIND_IN_SET(hoge, (select GROUP_CONCAT(hoge order by hoge desc) from receipt)) as rank from receipt; # PostgesQL select *, RANK() OVER (order by hoge desc) as rank from receipt; -- ~ごとのランクが知りたい場合、`PARTITION` 関数が使える SELECT *. RANK() OVER (PARTITION BY hoge ORDER BY huga) as ranking from receipt;
コラム 1: OVER 句
ウィンドウ関数呼び出しの際、常に含まれる。OVER 句は、ウィンドウ関数による処理の問い合わせの行がどのように分解されるかを厳密に決定する。
参考: ウィンドウ関数
ウィンドウ関数は現在の行に何らかとも関係するテーブル行の集合に渡って計算を行います
連番をふる
ROW_NUMBER() 関数を用いる
OVER 句と組み合わせることで、rank っぽく使える
重複削除
DISTINCT 関数を用いる。
DISTINCT column_name(, column_name)
で用いるのが一般的?
集約関数
複数の入力行から 1 つの結果を計算する。
参考: 2.7. 集約関数
中央値
残念ながら PostgresQL には MEDIAN 関数のようなものはない 代わりに 50 パーセンタイルを求める
SELECT store_cd, PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY amount) AS amount_50per FROM receipt GROUP BY store_cd ORDER BY amount_50per DESC LIMIT 5;
分散
WITH 問い合わせ
1つの問い合わせのために存在する一時テーブルを定義
WHERE句のサブクエリ
WHERE句に集計関数を記述することは出来ない。(WHERE AVG(amount) >= 10 は ×)
このように WHERE 句で判定する条件をレコードの問い合わせ結果で使う場合、サブクエリを利用する
select * from products where price > (select AVG(price) from products)
COALESCE 句
一生読み方覚えられない (コウアレスみたいな)
COALESCE(expr1, expr2) = CASE WHEN expr1 IS NOT NULL THEN expr1 ELSE expr2 END
直積
CROSS JOIN のこと。
NTT コミュニケーションズのインターンシップに参加しました
はじめに
2 月 14 日から 25 日までの 2 週間1、NTT コミュニケーションズのインターンシップに参加させていただきました。 せっかくなので熱が冷めぬうちにブログをまとようと思います。
インターンシップ概要
職場体験型インターンシップ| NTT コミュニケーションズ より引用
クラウドサービスにおける仮想サーバ基盤の開発
● 業務内容
クラウドサービスにおける IaaS 環境の開発に携わって頂くことで、IaaS 環境がどのように構成され、お客様に仮想サーバとして提供されているのかを経験して頂きます。
・Smart Data Platform (SDPF)における、仮想サーバを提供するための基盤開発(スクラム)
・OpenStack を用いた仮想基盤開発
参考: https://event.cloudopsdays.com/codt2021/talks/15
● 応募条件
【必須】
・Linux を利用したことがあり、基本的な操作が可能であること。
・Git/GitHub を利用し、ソフトウェア開発経験がある
・Ansible を利用した構築経験があること。
・Python を利用した開発経験があること。
【推奨】
・仮想化環境の構築経験があると望ましいです。(KVM/QEMU)
・OpenStack を利用した仮想環境の利用経験があると望ましいです。
参加のきっかけ
就活に向け秋冬インターンを探していた昨年 11 月末、「現場のエンジニアと一緒に解く!コーディング体験 | NTT コミュニケーションズ」 に参加しました(これはこれで面白かった)。
自分はこれまで上位のアプリケーションレイヤメインで開発していたこともあり、正直仮想化周りの興味がなかった2知識が乏しかったのですが、この 1 day イベントを期にクラウド基盤開発に興味を持った & 知り合った社員の方から NTT コミュニケーションズでの取り組みを伺ったことから、同チームコースのインターンシップに申し込みました。おそらくイベントに参加していなかったらインターンも応募してなかったのではないでしょうか?
いくつか選考を経て晴れて合格通知を頂いたので、2 週間の業務体験に励む運びとなりました。
インターンシップで取り組んだこと
私が配属された仮想サーバチーム(通称 VS チーム)では、OpenStack をベースとする SDPF のクラウドサービス基盤を開発しています。OpenStack の中でも Nova/Cinder/Glance/Masakari といったコンポネントを取り扱っており、まさに仮想マシンインスタンスの中核を担う領域と言えるでしょう。
そもそも私は OpenStack もなーんとなく知っている程度3だったので、オンボーディングのレクチャーはとても勉強になりました。NTT コミュニケーションズ が提供するサービスの概要から QEMU/KVM の仮想化まで網羅していただけでなく、ハンズオンも取り入れながらレクチャー頂いたことで、その後の IS を進めるにあたって必要な知識を短時間で身につけることができました。特に Ansible を活用した大規模システムの CI/CD 運用周りの内容は非常に面白かったです。
充実したレクチャーを経て、いよいよインターンシップ(以降 IS)のメインテーマとして OpenStack のバージョンアップに伴うログ基盤の改修に向けた検証に取り組みました。
第 1 ステップでは商用ログの分析を行いました。商用サービスに届いた実際のログを解析し、時系列ヒストグラムを作成することでリージョン別/コンポネント別/曜日別のリクエストの特徴を確認しました。社員の方と共有した結果、これまで認識していなかった(であろう)特徴が発見できたことが分かり、興味深い結果になったと思います。
第 2 ステップでは、ログ分析から得られた結果をもとに負荷試験を行いました。
k6 という負荷試験ツールを用いて商用環境を模したリクエストシナリオを実行し、ログ基盤、特に Elasticsearch サーバやコントローラノードにどの程度の負荷がかかるかを確認しました。
自分は JMeter と呼ばれる Apache 製のツールを使ったことがあるのですが、今回の IS で用いた k6 は、テストシナリオの実行エンジンに若干のクセがあるものの、 JavaScript でシナリオが書ける・公式のサンプルシナリオ集が充実しているなど、かなり使い易い負荷試験ツールという印象が残りました。
また、負荷の確認には Datadog という SaaS 型の運用監視サービスを利用しました。Docker イメージが配布されていることから、OpenStack の各コンポネントで Docker コンテナを立てるだけで配置が完了します。あとは Datadog のダッシュボードをカスタマイズすれば様々なメトリクスでマシンの状態を監視することができるので、構築はラクチンでした4。
パラメータを調整し様々なシナリオを実行、ホストの状態を監視するといったことを繰り返すことで、負荷を確認していきました。CPU/io/ネットワーク/ディスク/ボリューム/応答時間等の観点からホストの負荷を観察し、社員の方と結果を共有しました。具体的なログ基盤の要求性能を提案するまでには至りませんでしたが、Elasticsearch やコントローラーノード、 envoy と呼ばれるプロキシコンポーネントのインスタンスサイズを決定する一助になったそうなので、IS で一定の成果を残せたことを非常に嬉しく思います。
参加イベント
ただ上記の業務をこなすだけでなく、2 週間の間にいろいろなイベントに参加させていただきました。
- Sprint planning/review/retrospective
- Journal Club
- 朝会/夕会
- Lunch 会
- OpenHub 講演
Sprint meeting はアジャイル開発を採用する VS チームの主軸となるミーティングです。社員の方がどのような業務をどのように進めているか、間近で体感することが出来ました。IS での取り組みについて発表する時間も何度か頂けたので、緊張しながらも社員の方と直接議論できたのは非常に貴重な体験でした。
また Journal Club と呼ばれる社内勉強会にも 2 回参加しました。技術書の書評を始めとした業務に関連する内容のほかにも、英語の学び方といったユニークな回まで様々あったようです。自分も僭越ながら dotfiles5 についてお話させていただきました。結構ウケが良くて LT にちょうどいいんですよね、1 年近く改修してないけど。
職場環境
オミクロン株の流行もあり全日リモート開催となったものの、なんら支障をきたすことなく業務をこなすことができました。
タスク管理はプロジェクト管理ツールで一元化しており、業務で必要なドキュメントも全て整備されていました。話によるとコロナ以前から体制が出来ていたので、フルリモートへの移行もそれなりにスムーズだったとか。ちなみにドキュメントツールはほぼ全てアクセス可能にしていただいていたので、暇を見つけてはチラ見していました。時間があればもっとサーフィンしてみたかったです。
加えて魅力的だったのがフレックスタイム制です。研究室と就活の都合上、1 時間だけインターンを抜けざるを得ない日がいくつかあったのですが、分断したり翌日にまわしたりといった対応が可能でした。また社員さんも病院に行ったりサウナへリフレッシュしに行ったりと、かなり柔軟な働き方をされているようでした。
また Slack や NeWork 上でのコミュニケーションも活発だったのが印象的でした。節々にエンジニアっぽい雰囲気を感じたので、個人的には波長が合うなぁと居心地の良さを感じていました6。この心理的安全性はチーム由来のものではありますが、トレーナー、チームメンバー、さらに他チームの社員さんまで(?!)、たった 2 週間の IS 生である自分をあたたかく迎え入れてくださったことで、多くの方と交流できたと思います。改めてありがとうございました。
感想
1day イベントを皮切りに色々な巡り合わせを経て参加に至ったインターンシップでしたが、非常に充実した 2 週間になりました。
「大規模プラットフォームを支える基盤システムの全容を知りたい」という私の希望に合致したテーマをもとに、技術的な部分は勿論のこと、業務の進め方や考え方など、あらゆる箇所で勉強になる経験に触れた期間だったと思います。
特に、「何をゴールにその技術を採用するのか」「何を根拠にプロジェクトを進めていくか」といった目的意識の重要性は非常に濃く自分の中で印象に残っています。様々なメトリクスから観測したホストマシンの状態からどのような推論を得て、次の負荷試験のパラメータを決めていくか、のような業務を通じたミクロ視点で学んだだけでなく、参加したミーティングの議論の中からも、チームのマインドとして根付いていることを肌で感じることが数多くありました。
これまではネットワークインフラのイメージが強かった NTT コミュニケーションズですが、プラットフォームサービス開発の業務・環境・実際に携わる人の働き方を直接体験でき、とても良い経験になったと思います。自身の成長に繋がっただけでなく、私が漠然と描いている理想のエンジニア像が垣間見えたような気がしています。
NTT コミュニケーションズの皆様、なにより二週間つきっきりで指導してくださったトレーナーさん、短い期間でしたが大変お世話になりました。ありがとうございました。
Go言語でInteractiveなSlack Botを作ってみた
まえがき
最近就活に現を抜かしていたら、修士研究に背中を刺され重傷を負った ino です。
今回はアルバイト先の業務改善として、slack bot を作成しました。 bot 作りは、公式の提供する機能が充実しているが故に初手で詰まってしまうことも多いため、本ブログが参考になると幸いです。
なお、作り方をググると API Gateway と AWS Lambda で構成している方がほとんどですが、勉強のため Go でイチから作成しました。よってサーバレスではありません。 温かい目で見守っていただけると幸いです。
作成した Bot が出来ること
基本機能
Bots: 様々なチャンネルに招待可能Event Subscriptions: メンション(@hogefuga) での呼び出しに応答可能Permissions: チャンネルへメッセージを投稿可能Interactive Components: ユーザのアクションに応じて次の動作を決定可能
これらについては、Slack App が提供する Feature を参照ください。
ユースケース
本 Bot は、会議室予約システムを目指して作成されました。具体的なアクションフローは以下の通りです。
- チャンネルにボット(以降
@予約くん)を招待する @予約くんと呼ぶと、現在の予約一覧を返す@予約くん reserveと呼ぶと、以下の予約手続きに進む- 部屋名、開始時間、終了時間を指定する
- 確認ボタンを押して予約を実行する
- 重複判定を行い、空いていた場合、DB に格納する
- 予約完了メッセージをチャンネルに投稿する
@予約くん resetと呼ぶと、全ての予約を削除する
※ 予約変更機能は v1.1 で実装予定(忘れてた)。
補足
- 最近は Socket Mode を利用した開発が推奨されているようですが、セキュアな WebSocket サーバの作り方に自信が無かったので従来通り(?) ngrok を使っています。
- Go × Slack API のデファクトスタンダードとなっている slack-go/slack: Slack API in Go ですが、公式の SDK ではないことに注意しましょう。不親切なドキュメントや理不尽な沼に寛容な人向けです。無理な人はおとなしく bolt を使いましょう。
- そういうのはいいからコードを早く見せろ!という人は こちら 。
Slack App の準備
Go で Slack Bot を作る (2020年3月版) - Qiita のブログが丁寧に書かれているので、この通り行えば ok です。 おおよその手順は以下の通り
- Slack API: Applications | Slack からアプリを作成
Basic Information>App Credentials>Signing Secretの値を控えるOAuth & Permissions>Scopesにchat:writeを追加- ここで一旦 URL Verification 用のエンドポイントを実装し、デプロイを行う。
Event Subscription>Enable Events>Request URLでデプロイ先 URL の承認を行う。そして 同ページ >Subscribe to bot eventsからapp_mentionを追加。- これにより
chat:writeとapp_mentionの権限を持つアクセストークンに更新される。手元の .evn ファイルの更新とアプリのインストールを行う。 Interactivity & Shortcuts>Enable Interactivityを ON >Request URLにアクション用のエンドポイントを入力
多分 slack api 側でやることは以上です。
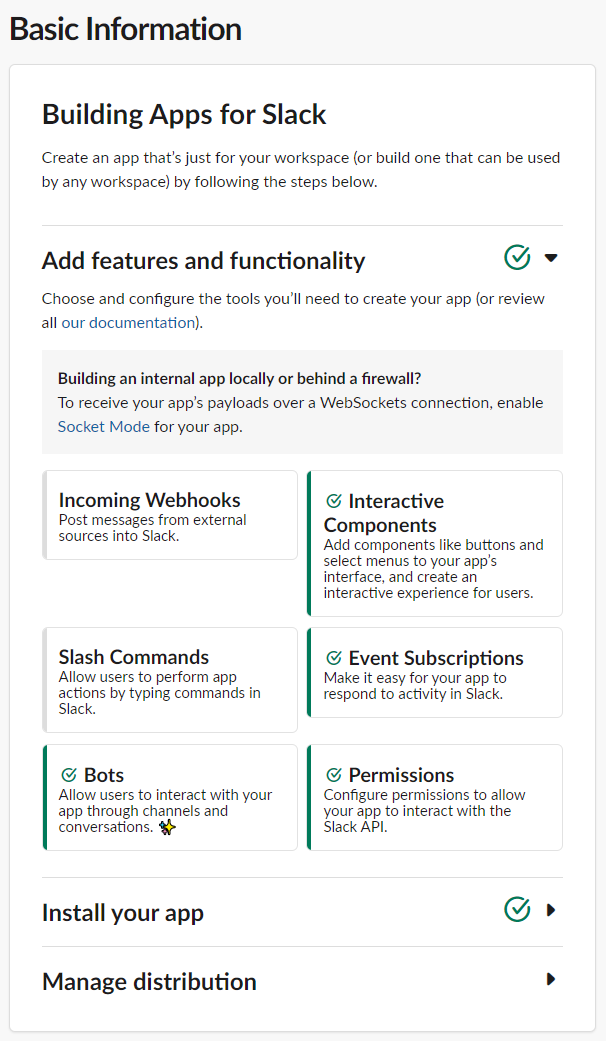
Basic Information が以下のように 4 つ✔ついていたら ok。
Go の準備
ngrok
ローカルに立てたサーバを一時的に外部に公開してくれる ngrok というサービスを使って、開発を行います。
# Sign up ngrok # Download ngrok-linux-package $ sudo tar -C ~/.local/bin -xzf ngrok-stable-linux-amd64.tgz $ chown USER:GROUP ~/.local/bin/ngrok # if you need
Go アプリ
ファイル構成は以下の通り。
. ├── api/ │ ├── actions.go │ ├── events.go │ ├── middleware.go │ ├── reserve.go │ └── server.go ├── util/ │ └── config.go ├── .env.sample ├── .gitignore ├── README.md ├── go.mod ├── go.sum └── main.go
重要箇所を抜粋して解説します。
Credentials
本アプリは以下の 2 種類のシークレットを必要とします。
- signing secret
- bot token
前者は Slack App へのリクエストが slack からであることのシークレット、後者は Slack App が Slack API を叩く際に必要なトークンです。後者に関しては Scope と紐づいているので、適宜機能追加に応じて更新する必要があることに注意。
エンドポイントごとに認証作業を行うのは面倒なのでミドルウェア化しましょう。
func slackVerificationMiddleware(config util.Config, next http.HandlerFunc) http.HandlerFunc { return func(w http.ResponseWriter, r *http.Request) { verifier, err := slack.NewSecretsVerifier(r.Header, config.SlackSigningSecret) if err != nil { w.WriteHeader(http.StatusInternalServerError) return } bodyReader := io.TeeReader(r.Body, &verifier) body, err := ioutil.ReadAll(bodyReader) if err != nil { w.WriteHeader(http.StatusInternalServerError) return } if err = verifier.Ensure(); err != nil { w.WriteHeader(http.StatusBadRequest) return } r.Body = ioutil.NopCloser(bytes.NewBuffer(body)) next.ServeHTTP(w, r) } }
TeeReader ってこういう時に使うんですね。
エンドポイント
Slack App では、Event API と Interactive Components を使います。 最小限のボットでは前者のみで十分ですが、今回は予約時間の指定などを行うため後者の機能も利用し、より対話的な bot を作成します。
まずは Event API 用のエンドポイント作成。パス ("/slack/events" の部分) は任意です。
http.HandleFunc("/slack/events", slackVerificationMiddleware(srv.config, func(w http.ResponseWriter, r *http.Request) { body, err := ioutil.ReadAll(r.Body) handleError(err, w, http.StatusInternalServerError) eventsApiEvent, err := slackevents.ParseEvent(json.RawMessage(body), slackevents.OptionNoVerifyToken()) handleError(err, w, http.StatusInternalServerError) srv.handleEventAPIEvent(eventsApiEvent, body, w) }))
*http.Request.Body から []byte 型のボディを抜き出した後、slackevents.ParseEvent を用いて json に直します。なおドキュメント1を読めば分かりますが、slack api では独自形式の json を通して挙動が制御されていきます。
続いて Interactive component 用のエンドポイント作成。
http.HandleFunc("/slack/actions", slackVerificationMiddleware(srv.config, func(w http.ResponseWriter, r *http.Request) { var payload *slack.InteractionCallback fmt.Println(r.FormValue("payload")) err := json.Unmarshal([]byte(r.FormValue("payload")), &payload) handleError(err, w, http.StatusInternalServerError) srv.handleActionPayload(payload, w) }))
先程のようなパース関数が用意されていない代わりに、slack.InteractionCallback という型が用意されています。json.Unmarshal を用いてペイロードを slack.InteractionCallback 型に直し、以降のハンドリングに使います。
Event API
今回は app:mention を使います。その他のイベントは Events API types | Slack を参照ください。ここに無いものは Interactive Components として扱う、という認識でいいんですかね(あまり分かってない)。
func (srv *Server) handleEventAPIEvent(eventApiEvent slackevents.EventsAPIEvent, body []byte, w http.ResponseWriter) { switch eventApiEvent.Type { case slackevents.URLVerification: ... case slackevents.CallbackEvent: innerEvent := eventApiEvent.InnerEvent switch event := innerEvent.Data.(type) { case *slackevents.AppMentionEvent: srv.handleAppMentionEvent(event, w) } } } func (srv *Server) handleAppMentionEvent(event *slackevents.AppMentionEvent, w http.ResponseWriter) { message := strings.Split(event.Text, " ") var command string command = message[1] switch command { case "ping": _, _, err := srv.slack.PostMessage(event.Channel, slack.MsgOptionText("pong", false)) handleError(err, w, http.StatusInternalServerError) case "reserve": text := slack.NewTextBlockObject(slack.MarkdownType, "利用する部屋を選択してください", false, false) textSection := slack.NewSectionBlock(text, nil, nil) ... // 部屋・時間の選択と確認ボタンのコンポネントを用意する inputBlock := slack.NewActionBlock(_selectRoomBlock, roomSelectMenu, startTimePicker, endTimePicker) actionBlock := slack.NewActionBlock(selectRoomBlock, confirmButton) fallbackText := slack.MsgOptionText("This client is not supported.", false) blocks := slack.MsgOptionBlocks(textSection, inputBlock, actionBlock) _, err := srv.slack.PostEphemeral(event.Channel, event.User, fallbackText, blocks) handleError(err, w, http.StatusInternalServerError) } }
slackevents.EventsAPIEvent.Type に応じて条件分岐を行います。
URLVerification については Using the Slack Events API | Slack を参照ください。
CallbackEvent が、EventAPI のメインの型? になります。slack-go/slack では、EventsAPIEvent は outer / inner の 2 層で構成されているので2、innerEvent を取り出してから詳細な条件分岐を行います3。
今回は event.Text から取得できるメッセージをスペース区切りでパースし、その先頭をコマンドとして扱ってみました。
補足: チャンネルへのポスト 2 種
slack bot が利用できるメッセージポストには 2 種類あり、一つは通常の投稿、もう一つは特定のユーザへの限定投稿(DM ではない)になります。
前者: func (api *Client) PostMessage(channelID string, options ...MsgOption) (string, string, error)
後者: func (api *Client) PostEphemeral(channelID, userID string, options ...MsgOption) (string, error)
Bot とのインタラクティブなやり取りには特に後者が使いやすいのでオススメです。
Interactivity
Event API では表現できない、ユーザとの対話的アクションに Interactive Components を利用します。コンポネントの配置用に Block Kit が提供されています。
Block Kit Builder4 を触れば分かりますが、Block Kit は Block - ActionBlock - BlockElement という三層から構成されているので、slack-go パッケージを使った最小構成のコードは次のようになります。
element = slack.NewHogeBlockElement(...) actionBlock = slack.NewActionBlock(BLOCK_ID, element) block = slack.MsgOptionBlocks(actionBlock)
この actionBlock に登録されている block element が操作されるたびに、事前に登録した Interactivity の request URL にリクエストが送られます。 このリクエストのハンドリング実装は以下になります。
func (srv *Server) handleActionPayload(payload *slack.InteractionCallback, w http.ResponseWriter) { switch payload.Type { case slack.InteractionTypeBlockActions: if len(payload.ActionCallback.BlockActions) == 0 { w.WriteHeader(http.StatusBadRequest) return } action := payload.ActionCallback.BlockActions[0] switch action.BlockID { case BLOCK_ID1: // actionBlock で指定した Block ID room := payload.BlockActionState.Values[_selectRoomBlock][roomNameAction].SelectedOption.Value startTime := payload.BlockActionState.Values[_selectRoomBlock][startTimeAction].SelectedTime endTime := payload.BlockActionState.Values[_selectRoomBlock][endTimeAction].SelectedTime ... replaceOriginal := slack.MsgOptionReplaceOriginal(payload.ResponseURL) _, _, _, err := srv.slack.SendMessage("", replaceOriginal, fallbackText, blocks) handleError(err, w, http.StatusInternalServerError) case BLOCK_ID2: ... } } }
補足: どうやって「部屋名」「開始時間」「終了時間」の 3 つを受け取るか
上記で述べた通り、「block element が操作されるたびに」リクエストが飛んできます。つまり roomSelectMenu、startTimePicker、endTimePicker をまとめた action block の Block ID で条件分岐を行っても、payload.ActionCallback.BlockActions に格納されている Action は操作した 1 つのみです。
色々調べた結果(かなり沼った)、payload.BlockActionState.Values に他のパラメータが全て格納されていました。3 入力を束ねる ActionBlock の他に確認ボタン用の ActionBlock を用意し、それをトリガーとしてイベントを発火させることで、payload.BlockActionState.Value から必要な情報を取得することが出来ます。
本ブログで一番大事なところなので、誰かの時間を救うことが出来たら本望です。
また、もっと良い方法があれば是非教えて下さい。
最後に

次はサーバーレスの実装かなー
【2021年夏】Docker再入門
なんとなく Docker を使っていたので再入門。
スキーマ駆動開発を試してみた
経緯
API 開発において、ドキュメントは重要です。ではそれをどう作るのか。
(RESTful) API のマシンリーダブルな仕様書に OpenAPI/Swagger を採用し、Swagger UI でドキュメントを閲覧する、というのは近年よく見られる技術スタックです。一方、いざ開発においてスキーマをいつどのように定義するのか、というのは以下の2つに大別されると思われます。
1 つ目のアプローチは、実際の API の実装から OpenAPI を作り出す方法です。自分のアルバイト先でもこの方法が採用されており、Rswag を用いて rspec のテストコードから Swagger ファイルを自動生成しています。このアプローチは、 API サーバの実装から絶対に乖離しないという圧倒的なメリットを持っており、フロント側では安心して Swagger ファイルを利用することができます。一方のデメリットとして、開発全体から見ると「API の実装 → フロントの実装」というフローが固定されてしまい、ともすれば API 開発がボトルネックとなってしまう恐れがあります。
そこで 2 つ目のアプローチとして、ピュアな Schema Driven Development (SDD) を採用するという方法があります。すなわち OpenAPI の仕様書を先に作り、それに則り API 開発 / フロント開発を進めるという手法です。フロント側は特に変更点がありませんが、API 側としては Test Driven Development のような開発スタイルを求められるようになります。
後者の SDD について試したことがなかったので、Pros/Cons を理解するためにも超簡単に実装してみました。
実装
環境
(committee の GitHub スター数は rswag の半分ほどなので、やっぱり前者のアプローチを用いることが多いのでしょうか 🤔 1)
OpenAPI のドキュメント
とりあえず適当に書きます。
openapi: 3.0.1 info: title: Swagger Example description: Example API version: 1.0.0 tags: - name: Channel description: Channels on YouTube - name: Video description: Videos on YouTube paths: /channels: get: tags: - Channel summary: Get an index of channels operationId: getChannels parameters: - name: page in: query description: page required: false schema: type: integer - name: per in: query description: per required: false schema: type: integer responses: 200: description: successfully operated content: application/json: schema: type: array items: $ref: "#/components/schemas/channel" 404: description: failed to operate content: application/json: schema: $ref: "#/components/schemas/error" /videos: get: tags: - Video summary: Get an index of videos operationId: getVideos parameters: - name: page in: query description: page required: false schema: type: integer - name: per in: query description: per required: false schema: type: integer responses: 200: description: successfully operated content: application/json: schema: type: array items: $ref: "#/components/schemas/video" 404: description: failed to operate content: application/json: schema: $ref: "#/components/schemas/error" components: schemas: error: type: object properties: status: type: integer message: type: string additionalProperties: false required: - status - message channel: type: object properties: id: type: integer title: type: string channel_id: type: string description: type: string nullable: true required: - id - title - channel_id video: type: object properties: id: type: integer title: type: string video_id: type: string channel_id: type: integer channel: $ref: "#/components/schemas/channel" description: type: string nullable: true published_at: type: string nullable: true required: - id - title - video_id - channel_id
モデル
Channel モデルと Video モデルを用意します。各カラムの意味は某動画投稿サイトをイメージして頂けると分かると思います。

コントローラー
お試しなので Channel Video のレコード全てを返す 脳死 GET /channels GET /videos を用意します(kaminari のページネーションを導入しているので page, per は受け取ります)。
JSON シリアライズ
ActiveModelSerializer を使います。
とりあえず工夫することも無いので attributes(*Channel(or Video).column_names) で全部返します。
committee 導入
公式の README だけでは詰まることも多かったので、詳しく記述していきたいと思います。
gem インストール
Gemfile に以下を記述。
gem 'committee' gem 'committee-rails'
E2Eテストでのみ用いる場合は group は dev, test で十分ですが、リクエストのバリデーション機能も提供しているので :default グループにインストールしていいと思います。
config を書く
rswag のようなインストールコマンドは存在しないので、config は自分で設定します。
書く場所は config/initializers/ 下でもよいのですが、とりあえずテスト時だけでよいので spec/spec_helper.rb に書くことにしました(と言いつつ helper ファイルが何者なのか分かってない & リクエストバリデーションのために config ファイルを作ったほうがいいかも)。
require "committee" require "committee/rails" RSpec.configure do |config| ... (中略) ... # Config committee config.include Committee::Rails::Test::Methods config.add_setting :committee_options config.committee_options = { schema_path: Rails.root.join('schema/schema.yml').to_s, old_assert_behavior: false, # prefix: "/v1", parse_response_by_content_type: false } end
ここに定義している committee_options が committee-rails の README に書いてあるメソッドです。
また注意点として 2 つ挙げられます。
committee-railsのインポートはrequire committee/railsと書く- ラッパーライブラリを使う経験があまり無かったので詰まった
spec_helper.rbのインポートの順番
# This file is copied to spec/ when you run 'rails generate rspec:install' require 'spec_helper' # この行を後ろに持っていく ENV['RAILS_ENV'] ||= 'test' require File.expand_path('../config/environment', __dir__) # Prevent database truncation if the environment is production abort("The Rails environment is running in production mode!") if Rails.env.production? require 'rspec/rails' ...
検証
spec を実行してみます。
$ bundle exec rspec spec/requests/ .. Finished in 0.07942 seconds (files took 0.7994 seconds to load) 2 examples, 0 failures
成功したけどこれじゃ分からんので型情報を改変します。
components/schema/channel の description にある nullable: true を消してみましょう。
$ bundle exec rspec spec/requests/channels_spec.rb
F
Failures:
1) Channels GET /channels returns an index of channels
Failure/Error: assert_response_schema_confirm
Committee::InvalidResponse:
#/components/schemas/channel/properties/description does not allow null values
# ./spec/requests/channels_spec.rb:13:in `block (3 levels) in <top (required)>'
# ------------------
# --- Caused by: ---
# OpenAPIParser::NotNullError:
# #/components/schemas/channel/properties/description does not allow null values
# ./spec/requests/channels_spec.rb:13:in `block (3 levels) in <top (required)>'
Finished in 0.04507 seconds (files took 0.78499 seconds to load)
1 example, 1 failure
Failed examples:
rspec ./spec/requests/channels_spec.rb:11 # Channels GET /channels returns an index of channels
お~
次は video_id を string → integer にしてみましょう。
$ bundle exec rspec spec/requests/videos_spec.rb
F
Failures:
1) Videos GET /videos returns an index of videos
Failure/Error: assert_response_schema_confirm
Committee::InvalidResponse:
#/components/schemas/video/properties/video_id expected integer, but received String: "HOGEHOGE123"
# ./spec/requests/videos_spec.rb:13:in `block (3 levels) in <top (required)>'
# ------------------
# --- Caused by: ---
# OpenAPIParser::ValidateError:
# #/components/schemas/video/properties/video_id expected integer, but received String: "HOGEHOGE123"
# ./spec/requests/videos_spec.rb:13:in `block (3 levels) in <top (required)>'
Finished in 0.06637 seconds (files took 0.8193 seconds to load)
1 example, 1 failure
Failed examples:
rspec ./spec/requests/videos_spec.rb:11 # Videos GET /videos returns an index of videos
ええやん
感想
微妙。
何より OpenAPI 書くのがだるい。
広義「プロダクト開発に直接関係ないもの」の心理的生産コストが高い場合、120%使われなくなるのが定めではないでしょうか。Stoplight Studio などを使えば GUI でも OpenAPI を錬成できるようですが、書き心地はしっくりこない。 rswag からわざわざ移行するほどかと言われれば……。
考察
とは言え、やはり大規模開発になるとスキーマ駆動開発が圧倒的優位に立つことは間違いないです。
そもそも Rails 一つ取っても、routes から controller、serializer、テストなど逐一スキーマの整合性を取りながら開発を進めていくのはかなり骨が折れます。しかも手作業。さらにアプリケーションの規模が大きくなり、責務が複雑になるからと言ってアプリケーション / スキーマを分割したくなったら?モノリシックな API では対応しきれず、新たに Go でマイクロサービスを始めたい!と決まったら?………などなど。実装 to OpenAPI には限界があります。
OpenAPI はスキーマ定義として確立しており、随する codegen も数多く開発されています。 スキーマファーストな開発スタイルに移行し、モデルもコントローラも極力 codegen で自動生成、可能であれば E2E テスト時だけではなく、モックサーバや実際のリクエストのバリデーションにも2使えたらな~というのがやはり理想的な開発になるのではないでしょうか?大規模開発している企業さんってどうしているんでしょうね。気になるところです。
逆に言えば、中規模かつモノリシックな API に対しては、「実装からスキーマを生成する」アプローチはかなりいい感じに機能すると思います。長蛇の YAML ファイルを読み解く必要もなく、仕様書と開発との打ち返しもありません。「API → フロント」に固定される開発フローが問題ない限り、ある程度開発スピードが求められるベンチャー初期のプロダクトや、規模感が小さい個人開発では有効な手段であると感じました。
結論
API ドキュメントの信頼性を高く、保守し続けられる運用を考えよう。
参考
- 各公式ドキュメント、レポジトリ
- Rails + RSpec + OpenAPI3 + Committee でスキーマ駆動開発を運用する Tips - Timee Product Team Blog
- API がカオスってたプロダクトで OpenAPI 対応やってみた
- committee を使った OpenAPI3 のバリデーション - Qiita
-
ブログ書き終えてから思ったのですが、モノリシックがちな Rails と openapi-codegen を組み合わせることは少なく、やはり相性良さそうな go-swagger は実用例が多そうですね。というか go-swagger のスター数 6.5k じゃん。↩
-
committee はこの機能も提供しているよう。けっこう強力だな。参考 → committee を使った OpenAPI3 のバリデーション - Qiita↩
俺のターミナル環境を晒す 2021 ~見た目だけじゃない!高機能かつ高速な環境を Git で管理しよう!~
はじめに
モノクロなターミナルの世界、使いづらくないですか?
私は開発環境が綺麗であればあるほど、美しいと感じます。「健全な精神は健全な身体に宿る」と言われるもの、エンジニアなら健全な開発は健全な環境を整えるべきだ!と一念発起し、我流 dotfiles の構築に取り組みました。
詳細
ソースコード
スライド
https://inox-ee.github.io/dotfiles (こちらはインターン先の勉強会にて発表したスライドになります)
結論
- dotfiles は利点しかない
- 新マシン移行時の環境構築の楽さ
- git 管理による再現性の高さ
- シェルスクリプトに強くなる
- 半自動化にも取り組んだ
【GitHub Actions & Marp-CLI】進捗報告用スライドを速攻で作る
見やすいからタイトルに【】を付けることが多かったけど、 バズりたいだけのブログに見える なんとなくダサいので外そうかなぁ
1. Marp とは
週例ミーティングや勉強会など、なにかとスライドに成果をまとめて発表する機会が多い今日この頃。 てきとうに見やすいスライドを作りたいけど、Adobe や PowerPoint でじっくりコトコト煮詰めるほどの時間はかけたくないよ~というそこのあなた、是非 Marp の門を叩きましょう。
Marp とは、Markdown の書式からスライドを捻出してくれるエコシステム1のことです。 Markdown to Slide なツールはいくつか存在しますが、Marp の強みは以下の機能をすべて備えていること。
- Based on CommonMark
- Built-in themes and CSS theming
- :star: Directives and extended syntax
- :star: Export to HTML, PDF, and PowerPoint
- :star: Marp family: The official toolset
- Pluggable architecture
- Fully open-source
エクスポート形式が多岐にわたることやシンタックスハイライトの記法を備えていることはかなり嬉しいところ。 特に HTML 形式での出力はかなり機能が充実しており、PDF では機能しない mp4 や GIF も埋め込める他、なんとプレゼンテーションモードも備えているので、どこかにデプロイしておけばそのまま発表が出来る(しかもコメントアウト箇所がノートになる。強すぎ)。

2. Marp CLI のススメ
先の章であげた機能群の中でもう一つ、Marp family: The official toolset の特徴も嬉しいところ。オープンソースなこともあり、本家だけでなく Marpit や Marp for VSCode2 など派生プロジェクトの開発も活発である。
今回はその中でも Marp CLI を紹介する。
Marp CLI はその名の通り Marp のエクスポートを切り出した CLI ツールである。npm で公開されているので npx @marp-team/marp-cli で使用可能である。便利。
その一方、
"Do you hate to install Node and Chrome locally?"
な人々もいるだろう(?) そのような人のため、Marp はなんと Docker image も公開している。神~
Marp-CLI on Docker の使い方
とは言え docker の使い方でいくつか躓いたところがあるので以下ポイントをまとめる。
ポイント 1:オプションの問題
Marp-CLI は高機能がゆえオプションがたくさんある。 typo や大文字小文字、フラグの指定忘れに注意。意外と時間を溶かした。
ポイント 2:ファイルパーミッションの問題
docker あるあるの問題。
Marp-CLI on Docker は変換対象のファイルが /home/marp/app/ に置かれる必要があるようで -v "$(pwd):/home/marp/app/" によりボリュームをマウントしている。
しかし、Docker 経由でファイルを作成することによりホスト OS 側からファイルパーミッションエラーが起きることがある。これはホストユーザとコンテナ内ユーザのユーザ ID が異なることが起因しているため、コンテナを動かす際に揃えてやる必要がある。
幸い公式から既に解決法が提示されており、-e MARP_USER="$(id -u):$(id -g)" オプションをつければ良いとのこと。-u $(id -u $USER) でもいい気がするけど検証してないです。
- 参考
ポイント 3:フォントの問題
PDF 変換時は適切にフォントを指定しないと、文字化けや簡体字っぽくなることがある。これは docker オプションで -e LANG="ja_JP.UTF-8" とした上で、markdown ファイル内の Front-matter で次のようにフォントを指定してやればよい。
style: |
@import url('https://fonts.googleapis.com/css2?family=Noto+Sans+JP&display=swap');
section {
font-family: 'Noto Sans JP', serif;
}
3. GitHub Actions で PDF 生成の自動化
PDF 生成は Marp for VSCode で十分なのだが、他端末で共有するときや教授に見せる時にわざわざ Google Drive にアップロードしてノート PC でダウンロードして共有ドライブにアップロードして……という動作が面倒だった。ということで PDF へのエクスポートは GitHub Actions に任せ、Artifactとして一時保存しておくのが楽やろ~と思い、作った。
レポジトリは こちら。
生成された PDF ファイルは、workflow の結果 を見れば Artifacts という項目にアップロードされている。クリックすればそのまま zip ファイルとしてダウンロードされるので便利。また保存期間もレポジトリの設定から編集できるので、各自調整してほしい(デフォルトでは 90days かな)。
[2021/04/20 更新] PDF のデプロイ先を、ncipollo/release-action を用いて Artifacts から Releases に変更しました。これによりファイル単位ではなく、Releaseのタグによってバージョン管理が可能となります。
基本的に前章で述べた注意点に気をつければこのまま使えるハズ。良かったら fork したり star つけたりしてください。
4. ToDo
パブリックリポジトリでは無制限で GitHub Actions が利用可能ですが、プロベートレポジトリでは 2000 min / month に制限されています。そのため Docker images は都度リモートから pull するのではなくローカルにキャッシュしておきたいところ。できたらまたブログ書くかぁ。